Law 31 · Safety & Security
The Lethal Trifecta
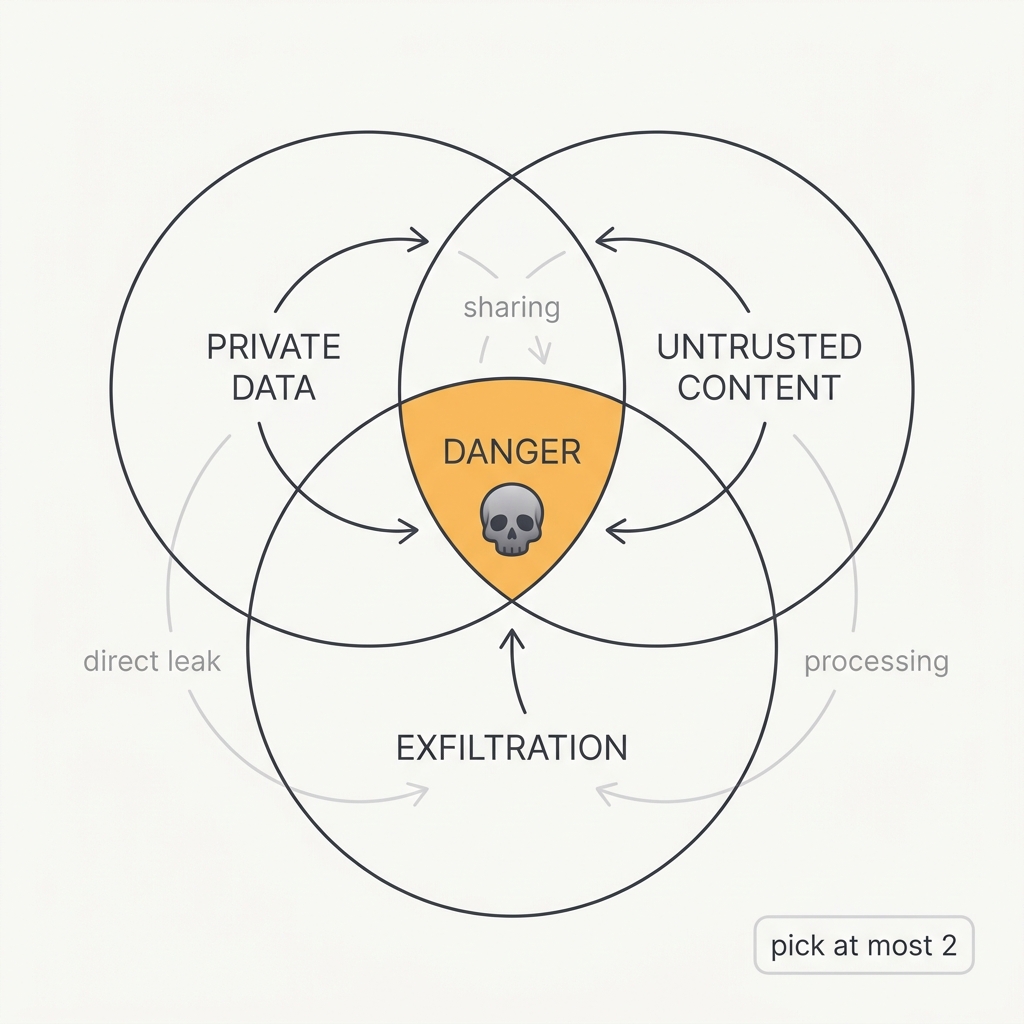
Private data, untrusted content, and an exfiltration path — pick at most two.
The principle
An agent becomes exploitable the moment it combines three capabilities: access to private data, exposure to untrusted content, and the ability to communicate externally. Any single poisoned input in that pipeline can steer it into stealing your data — no code vulnerability required. Guardrails won't save you, because the model cannot reliably tell where an instruction came from.
Why it happens
The vulnerability is structural, not a bug in any one component: the moment an agent can read private data, ingest content an attacker controls, and emit data to the outside world, a single poisoned input can chain those capabilities into exfiltration with no memory-corruption or code exploit involved. The model has no reliable way to distinguish a legitimate instruction from one smuggled inside retrieved content, so ignore malicious instructions style guardrails fail probabilistically and an attacker only needs to win once. Real instances follow the pattern exactly: a hidden instruction in a web page, email, or document tells the agent to read a secret and embed it in an outbound request, often disguised as a URL or image fetch. The defense is combinatorial, not detective: deny any one of the three legs and the chain cannot close, which is why removing a tool or isolating the data beats trying to filter the payload.
Watch for
- One agent context has access to secrets or private records AND processes text from emails, web pages, or user uploads.
- The same agent that reads untrusted input can also send email, make outbound HTTP calls, or write to a shared external store.
- Your only defense against malicious instructions is a system-prompt line telling the model to ignore them.
In practice
Your support agent reads from a customer's private ticket history, ingests the body of an inbound email, and can call a send_email tool to reply. That is all three legs: private data, untrusted content, and an exfiltration path. A customer pastes a request to forward another user's account details to an outside address into their email signature and the agent obliges, because it cannot tell that instruction apart from a real one. The fix is not a cleverer system prompt: drop one leg. Make the reply tool draft-only behind human review, or strip the agent's access to other customers' data when it is processing inbound mail.
Apply it
- For each workflow, enumerate all three capabilities (private data, untrusted input, outbound channel) and confirm whether one agent holds all three at once.
- If all three are present, break the chain: drop one tool, split the data access from the untrusted-input path, or route the outbound action through human review.
- Make any externally-communicating action draft-only or allowlisted to known-safe destinations rather than free-form.
The takeaway
Audit every agent for all three capabilities at once. If a workflow has all three, break the chain — remove a tool, isolate the data, or insert a human gate.