Law 34 · Safety & Security
Quarantine Untrusted Tokens
Let the privileged planner orchestrate, but never let it read the poison.
The principle
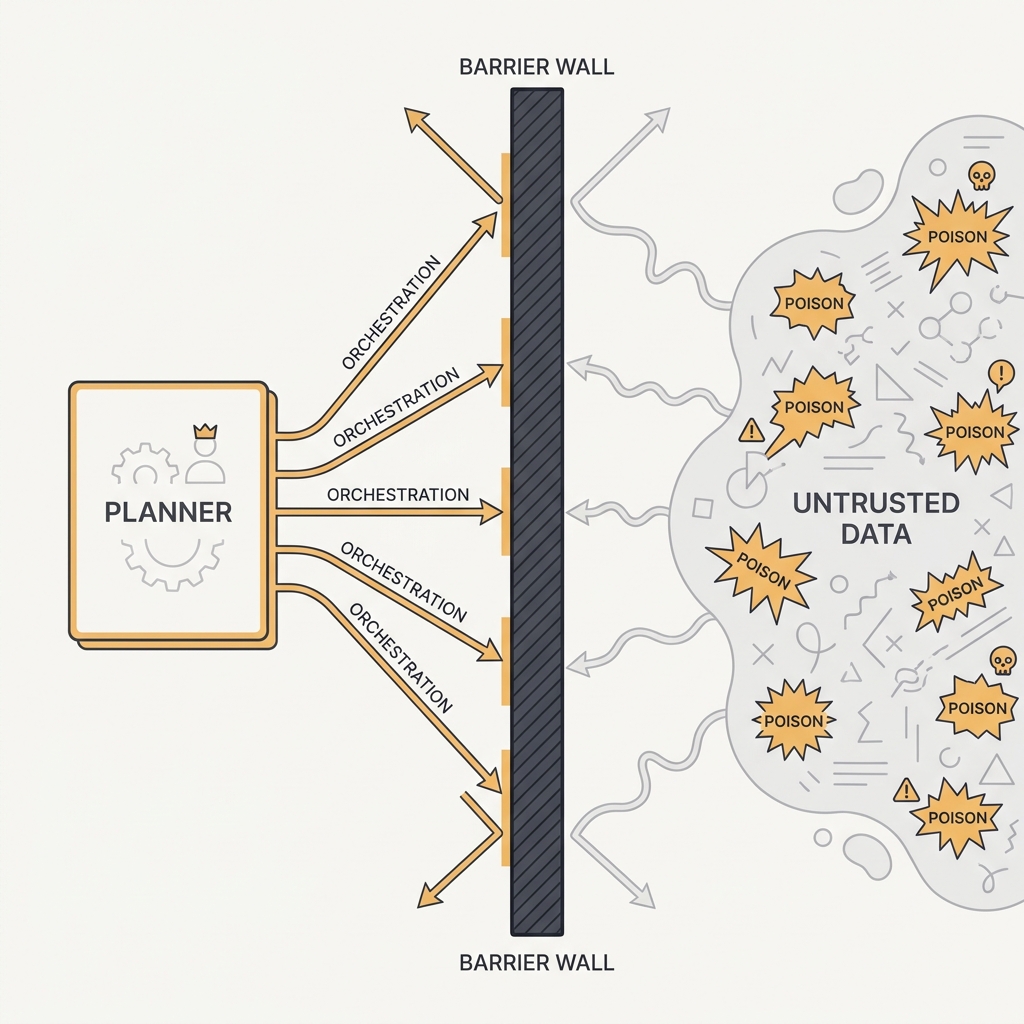
The Dual-LLM pattern splits the agent in two: a privileged model that holds tools and plans actions but never sees untrusted content, and a quarantined model that processes tainted data but has no tools and returns only opaque variables. The privileged model orchestrates the quarantined one without ever ingesting the bytes that could carry an injection. Security comes from the separation.
Why it happens
The Dual-LLM pattern enforces security by topology rather than by detection: a privileged model that holds tools and plans actions never sees raw untrusted bytes, while a quarantined model reads the tainted content but has no tools and returns only opaque, structured variables the planner manipulates by reference. Because the planner acts on symbols like a summary id or a sentiment label instead of the attacker-controlled prose, an injection buried in the source has nothing in the privileged context to grab onto. CaMeL, the 2025 refinement from Google DeepMind, hardens this further: the privileged model emits code in a constrained interpreter that tracks data and control flow as capabilities, and it provably blocked the prompt-injection scenarios in the AgentDojo benchmark without modifying the model itself. The security comes from the air gap between reading and acting, not from any classifier judging whether the content is safe.
Watch for
- The same model instance both reads scraped or user-supplied content and decides which privileged tools to call.
- Raw untrusted text flows directly into the context that holds tool access.
- There is no structured boundary forcing untrusted content to become opaque variables before the planner sees it.
In practice
You build a research agent that scrapes arbitrary web pages and also holds Slack and database tools. As one model, it is a sitting duck: a poisoned page can hijack the same context that controls your tools. Split it instead. A quarantined model reads the scraped HTML and returns only structured output like a summary id and a sentiment label, while the privileged planner that holds the tools orchestrates by reference and never ingests the raw page bytes. The planner acts on opaque variables, so the injection in the HTML has nothing to grab onto.
Apply it
- Separate the component that reads untrusted content from the component that can take privileged actions.
- Have the reader return only structured, opaque results (ids, labels, typed fields), never raw text the planner ingests.
- Let the privileged planner orchestrate by reference, so an injection in the source has no foothold in the acting context.
The takeaway
Isolate the component that reads untrusted content from the component that can act. Pass references and structured results between them, never raw tainted text.