Law 10 · Reasoning & Planning
More Thinking Can Hurt
Extra reasoning past the answer is wasted — or a wrong turn.
The principle
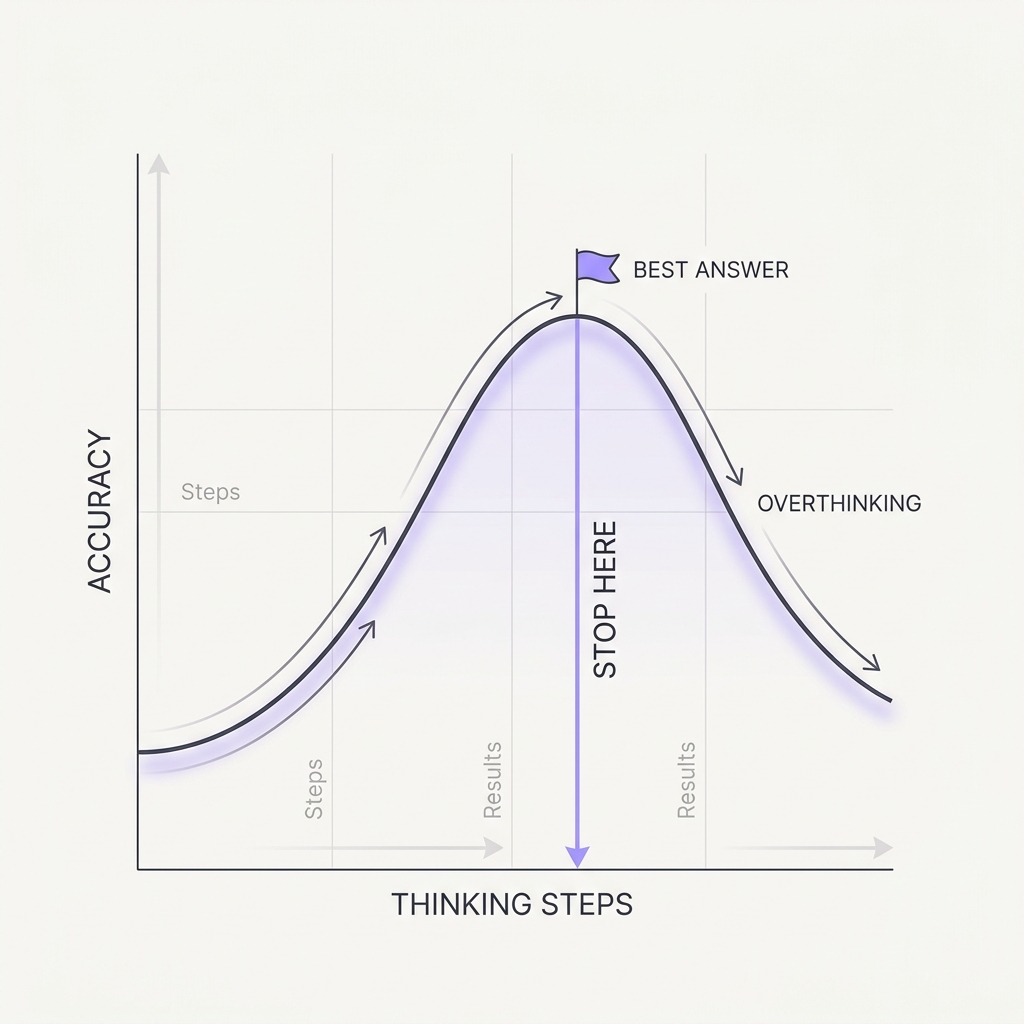
Reasoning models 'overthink': they pour disproportionate effort into trivial problems for minimal gain, and on harder ones, extended deliberation can talk them out of a correct initial answer. Reasoning depth has a sweet spot, not a monotonic payoff. An agent grinding tokens on a simple lookup burns latency and money; one that keeps re-deriving can reason its way to the wrong conclusion.
Why it happens
Reasoning depth has a sweet spot rather than a monotonic payoff because extended deliberation can revisit and overturn a correct initial answer, and the marginal token stops adding information once the answer is settled. Apple's Illusion of Thinking (2025) made the non-monotonic shape concrete: reasoning models increase their thinking effort with problem complexity up to a threshold, then counterintuitively reduce effort right as accuracy collapses, even with token budget to spare, and on simple problems they often find the right answer early then overthink their way to a worse one. The cost is two-sided: on trivial lookups the extra deliberation is pure latency and money for no gain, and on harder ones re-deriving can talk the model out of a right answer. The fix is to match the reasoning budget to difficulty, cap thinking on easy paths, and stop once a confident answer is in hand instead of letting the model wander.
Watch for
- Trivial lookups take seconds and cost multiples because everything is routed through extended reasoning.
- The model reaches a correct answer early, keeps deliberating, and lands on a wrong one.
- Longer thinking traces show no accuracy gain, or even a drop, on your easy cases.
In practice
You route every query through extended reasoning to be safe, and your 'what is the order status' lookups now take 8 seconds and cost 4x while occasionally talking themselves out of the correct status field. Reasoning has a sweet spot, not a monotonic payoff: trivial lookups get burned latency for nothing, and over-deliberation can overturn a right first answer. Match the thinking budget to difficulty, cap it on easy paths, and stop the moment you have a confident answer instead of letting it wander.
Apply it
- Match the reasoning budget to problem difficulty rather than maxing it out everywhere.
- Cap or skip extended thinking on simple, low-stakes steps like direct lookups.
- Stop once a confident answer is reached instead of letting the model keep re-deriving.
The takeaway
Match reasoning budget to problem difficulty. Cap thinking on easy steps, and stop once you have a confident answer instead of letting the model wander.