Law 28 · Evaluation & Measurement
The Judge Is Biased
An LLM grader reacts to length and position, not just substance.
The principle
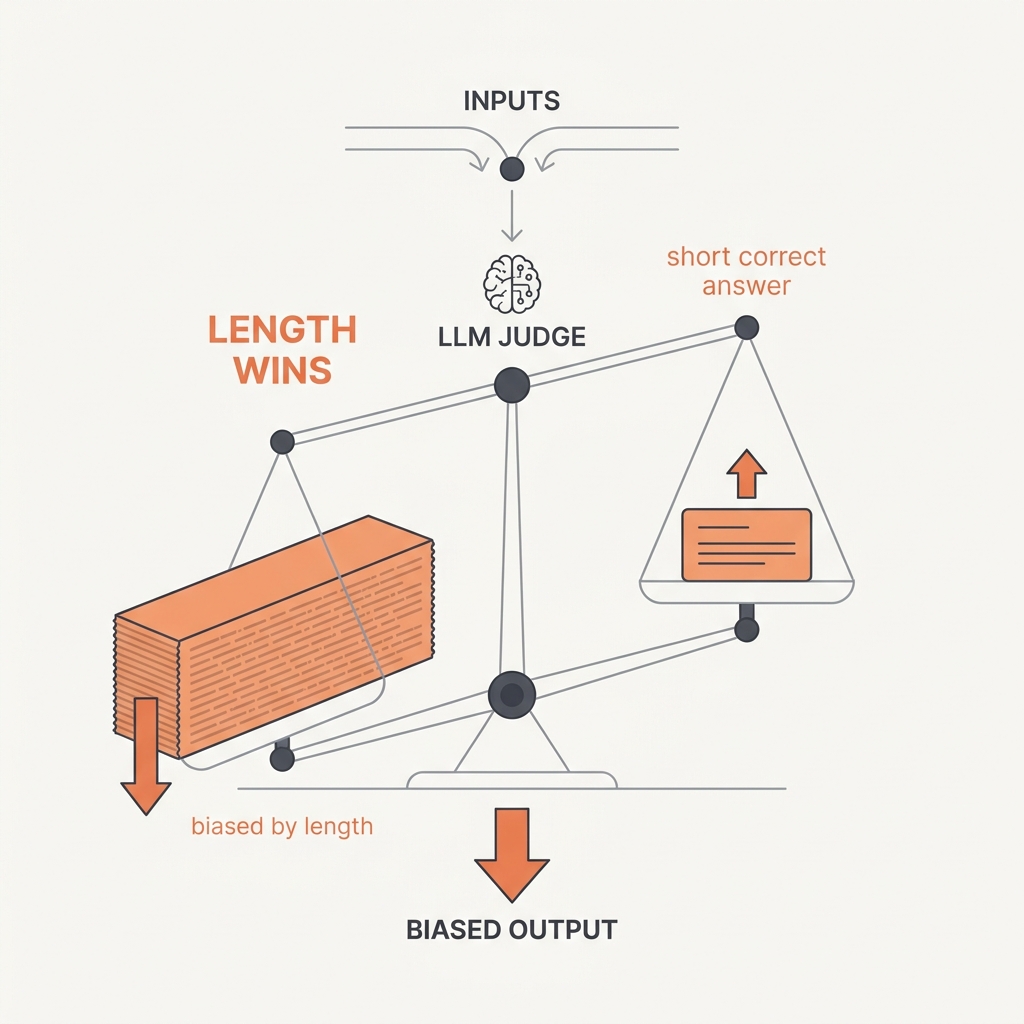
An LLM judge can match human preferences over 80% of the time — but only after accounting for systematic biases: position bias (favoring the first answer shown), verbosity bias (favoring longer answers regardless of quality), and self-enhancement bias (favoring its own outputs). It's a useful instrument, but an uncalibrated one that grades surface features as readily as substance.
Why it happens
An LLM grader is a model scoring text, so it inherits model biases and grades surface features as readily as substance: controlled studies measured position bias (favoring whichever answer is shown first), verbosity bias (favoring longer answers regardless of quality), and self-enhancement bias (favoring outputs from its own family). These are systematic offsets, not random noise, so they survive averaging and quietly skew A/B tests toward whatever is longer or shown first. A second failure mode is that the judge's rubric is itself unstable: the criteria a human or model applies shift as they see more outputs, so a fixed grading prompt may not capture what you actually care about. The judge is a useful instrument but an uncalibrated one, and it must be validated against human grades before its scores are trusted.
Watch for
- One variant wins your A/B tests and it happens to be the longer answer or the one shown first.
- A model is grading outputs from its own family with no independent cross-check.
- The judge's rubric was written once and never validated against human labels on real outputs.
In practice
You wire up an LLM-as-judge to pick the better of two agent responses and one variant mysteriously dominates every A/B test. It turns out the winner just writes longer answers and happens to be shown first, both of which the judge silently rewards regardless of substance. You were measuring verbosity and position, not quality. Swap the answer order and average both runs, control for length so a padded answer cannot win on bulk alone, and never let a model be the sole grader of outputs from its own family.
Apply it
- Swap answer positions and average both orderings to cancel position bias.
- Control for length so a padded answer cannot win on bulk, and never let a model be the sole grader of its own family.
- Validate the judge against a set of human-graded examples and refine the rubric until they agree.
The takeaway
Swap answer positions and average both orderings, control for length, and never let a model be the sole judge of its own family's output.