Law 37 · Architecture & Operations
Cascade Before You Escalate
Try the cheap model first; only the hard cases deserve the expensive one.
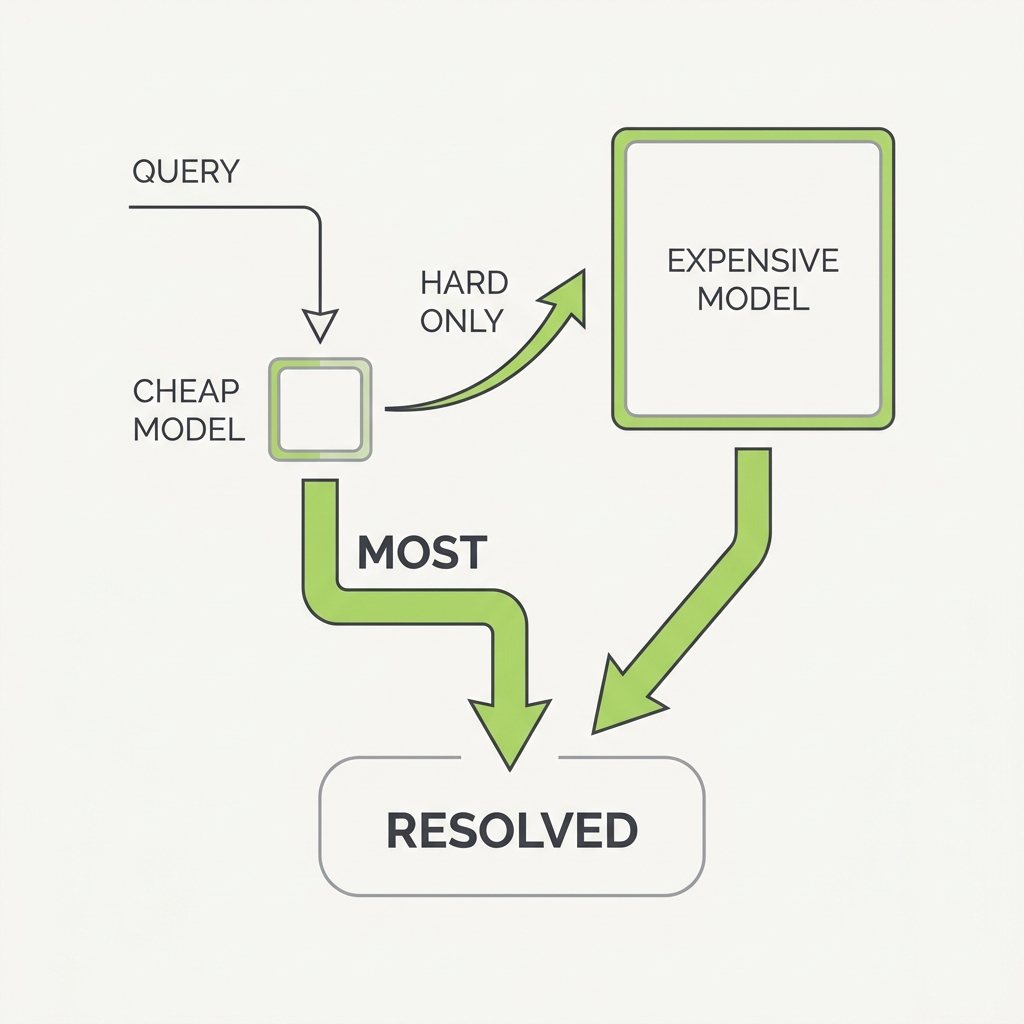
The principle
Most queries don't need your most powerful model. Routing requests through a cascade — a cheap model first, escalating to stronger models only when confidence is low — can match top-tier quality at a fraction of the cost. The price gap between models spans two orders of magnitude, so paying top dollar for every call is pure waste.
Why it happens
FrugalGPT showed that routing queries through a cascade (a cheap model first, escalating only when a scorer judges the answer inadequate) can match or beat the best single model while cutting cost by up to around 98% on their benchmarks, because most queries are easy and the price gap between weak and strong models spans roughly two orders of magnitude. The economic insight is that paying top-tier rates for the easy majority is pure waste: the value is concentrated in correctly identifying the minority of hard cases that actually need the expensive model. The hard engineering problem is the router, the deferral decision of when the cheap answer is good enough, since self-reported confidence is poorly calibrated; learned routers like RouteLLM address this with preference data and report over 2x cost reductions at matched quality. A cascade only pays off if the deferral signal is sound, so it must be validated against your own eval set, not assumed.
Watch for
- Every request hits your most powerful model, including high-volume classification or lookup tasks a small model handles.
- You have no measured deferral signal deciding when a cheap answer is good enough to keep.
- Cost scales linearly with traffic and the easy majority of queries dominates the bill.
In practice
Every call in your pipeline hits top-tier pricing, including the 80% of requests that are simple intent classification a small model nails perfectly. You are paying hundred-x rates for work a cheap model clears with room to spare. Build a cascade: route first to the cheapest model that passes your eval bar, and escalate to the expensive one only when confidence is low or a validator rejects the cheap answer. Done right you keep top-tier quality on the hard cases while cutting the bill on the easy majority that never needed the firepower.
Apply it
- Answer first with the cheapest model that clears your eval bar, and escalate only on failed or low-signal cases.
- Build a deferral check (a validator or learned router) rather than trusting the model's self-reported confidence.
- Validate the cascade against a labeled eval set to confirm escalated cases are the ones that actually needed the strong model.
The takeaway
Build a cascade: answer with the cheapest model that clears your eval bar, and escalate only on low-confidence or failed cases.